株式投資とファクター合成の論文(Hiraki&Watanabe 2019) -FDS非線形モデルの驚異的パフォーマンスについて- by yamamoto
 こんにちは、山本 潤です。今日は長期投資ゼミの勉強会と忘年会です。
こんにちは、山本 潤です。今日は長期投資ゼミの勉強会と忘年会です。
それはそうと、昨日は、今年出された興味深い論文を株の学校長期投資ゼミの有志と読み合わせを行いました。論文は一人で読むよりみんなで読んだ方がああでもない、こうでもないという「気づき」が得られますね。
論文はこちらです。
https://fdsol.co.jp/doc/rcv_20190912.pdf
国際大学 平木多賀人教授、アルバータ大学 渡辺雅弘准教授の共著論文「ファクター合成とポートフォリオ運用」を公開しました。金融データソリューションズ独自の銘柄スコア計算システム(特許登録番号:6320350)で提案される、RCV(Reciprocal Coefficient of Variation)方式によるファクター合成方法について、その理論的背景と株式運用における実証結果を提示した論文です。(FDS HPより)
日本株ロングショート戦略で年率40%を大きく超える成果が期待できるとあって、すごいことですね。
個別株のリターンを説明するファクターを1300を超えるファクターを作っているのですが、その作り方が非常に面白いものがあります。
株の学校長期投資ゼミで普段から最重要視しているリターンとリスクとの関係(インフォメーションレシオ)を論文では徹底して追求していて、なるほどなあと感心してしまいます。すごいこと考えたなと。実戦向きの完成度の高いシステムができるようです。過去データ、財務データとマーケットデータがあれば(ただし長期間のものが必要)、このシステムが構築できます。私はボトムアップですので、ボトムアップと組み合わせるととんでもない破壊力を持つと思います。このコラムでは、論文の解説をいたします。
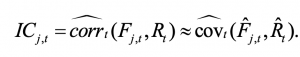 これを(1)とします。
これを(1)とします。
F_j,tはt時点でのj番目のファクター。実際のシステムではjは当初は1から9までの9ファクターを選んでいます。最終的にはjは1368まで拡張するのですから。R_tは個別株のt時点でのリターンです。チルダマークが上についている一番右の式のF tildeとR tildeはそれぞれの原系列を正規化、もしくは10分位等の序列化した系列です。正規化というのはz化。平均0、分散1にしたもの。序列化とは正数で序列化する、あるいは-xから+xまでゼロを中心にして序列化するなどの手法があります。ファクターの中には異常値があるのが通常ですので、arctanなどで区間を抑える工夫があるとよいでしょう。一つのjについても複数の系列を合わせて見ようという態度です。
何れにしても、t時点でのIC_j_tによって、一つのファクターと個別株リターンとの相関係数が出ます。正規化した系列を求めれば共分散の分母が1ですので相関=共分散になる。こう書いてくれると、ものぐさな私たちは、とにかく相関求めよう、正規化しなくていいから、などと軽口を叩きながら読み合わせに入ったのです。
場所は中央大学の数学科のドクタールーム(仮称)ですが、ホワイトボードが長いので便利。あれこれ書き込みながら作業を進めます。週末で私の指導教授のM先生は不在でした。専門外?の金融の論文を読んでいる=線形代数の復習してます、と言い訳をしようと思っていましたが、言い訳しなくても誰も何やってんのと覗きにきませんでした。(これが平日だと、何やってんのと外野がくることが多い。数学科のアットホームなところ)
主役は個別株のt時点でのリターン。それを説明する各々のファクターがNf個あるという想定です。
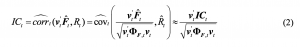
さて、(2)です。IC_j_tたちを集めます。つまり、Nf次元ベクトルにする。
F tilde_j,tたちに重みベクトルv_jたちを同数用意します。基本的には重みですので、v_jたちは正数かなと思っていました。
(2)によって、Nf次元からR(一次元)への写像を作ったわけですが、この段階では重みv_jたちは任意のベクトルで決定されていません。(2)のラージPhiはF_jたちのクロスセクション相関行列でNf x Nf行列。v_j転置を左からかけ、v_jを右からかけて重み付きの分散が計算できます。

ここで、重みベクトルv_j_tたちをどう決定するかという問題ですが、相関行列の逆行列を使えばよいことがわかります。ちなみに(2)のv_jたちに(3)を代入すれば写像の値が変わらない最大値となります。つまり重みv_jたちを最適化したわけです。sは任意の正数。

(4)の定式化がとても重要です。投資の基礎の基礎です。右辺の分子はウエイト付きのIC_j_tたちの時系列平均、分母は標準偏差となっています。large SigmaはIC_j_tたちの時系列共分散行列です。つまり単位リスク(説明力の不確かさ)あたりのリターン(=説明力の高さ)です。
この段階で時刻tの断面ではなく時系列情報が加味されました。つまり、IC_tよりも前のIC_tauたち、(tau < t)の情報が加味されたのです。
 (4)の最適化を行うのが(5)です。sは任意の正数。large Sigmaの逆数は先ほどの(4)式のlarge Simgaの逆行列です。
(4)の最適化を行うのが(5)です。sは任意の正数。large Sigmaの逆数は先ほどの(4)式のlarge Simgaの逆行列です。
ここまでで、個別株のリターンを時系列に説明できるファクターがほぼ特定されました。(ある銘柄でどのファクターが効いたのかが具体的に重みv_tたちを見ればわかる)

(6)は非常に重要。t時点のj番目のファクターのRCV_j_tとは過去のIC_j_tたちの平均を標準偏差で割ったもの。各々のファクターがどれだけ説明力があるのかを分子で示し、どれだけ説明力が不確かなのかを分母で示しています。説明力が高くても、不確かさが大きなものは信用できませんね。多くの多重回帰はこの点が考慮されていません。みんな平均は使うのですが、標準偏差で割らない。単位リスクあたりのリターンという基本形がここでも活躍します。

(7)は先ほどの(6)たちを集めただけのものです。ベクトルです。(6)を重みにすり替えるわけですね。至極当然のことですが、説明力が高くて、心配の少ないファクターの重みを高く、そうではないファクターの重みは低くなるわけです。ここまで来て、平均の符号が気になります。数学の理論構成では、正数だけでウエイトを構成するとかなり堅牢な理論になりますが、負数が入ると不安定なシステムになるからです。相関係数を利用するこのシステムの場合、負の数が多く含まれているはずです。ただ、株式投資には合っていると直感が働きます。何故ならば、あるファクターがプラス寄与する銘柄も、違う銘柄になればマイナス寄与になる。あるいは、あるファクターがある時期にプラスだがある時期にはマイナスになることは投資では当たり前のことだからです。

(8)はある特定の一つの個別株に対する時点tにおけるスカラです。(8)の最適化は(7)で求められています。これが一つの銘柄のt時点でのRCVtであり、どのファクターがt時点では最も確実に効いたか、そのファクターに大きな重みをつけて説明した値ですが、値が大きいほど、個別株リターンが外部ファクターでしっかり説明できたことになります。
ここまでで、Nfのファクターができる限りの説明力を持つように個別株ごとに違うウエイトを時刻tごとに決定しましたが、ここからファクターを拡張します。その拡張はユニークです。9つのF_jたちを選んだ後、さらに9つを追加。その追加の手法は、F_jたちにスペシフィックリスクを掛け合わせたものです。銘柄スペシフィックなリスクとは、9つのファクターでは説明できなかったリターンの残差部分です。残差は操作によってある正数を足し合わせて、全てプラスに直します。正数をかけるのですが、スペシフィックリスクの高い銘柄に再度、9つのファクターをかませることで、敗者復活戦的な系列に倍加したのです。これで18ファクターへ増えました。ファクターの中には、リターンと自己相関してしまう要素が紛れています。例えば、時価総額ファクターです。時価総額が大きくなる=株価が上昇するですから、明らかな自己相関です。すでに作った18のファクターからこの時価総額相関だけを取り除いたものを作ります。(作り直す)。そうすると新たに18のファクターが作れます。合わせて36にします。36のクロスセクションを考えると、36×36の共分散行列で対称成分の片方を除いた666のファクターが生まれる。36+(36×36-36)/2です。このクロスセクションによって、各要素間の関係を網羅することができます。この666のファクターは相関係数ですから、負の値があります。それを正数へと並行移動したものをそれぞれ作り666のファクターを新たに作ります。順位を保存したまま正数にすることと、負の値をそのまま活かすことをすることで、方向性と順位との関係を[増幅]します。
このように、最終的に1368のファクターを作ります。9つから出発しましたので、大変、多くなりましたね。
さて、ここで、銘柄と時刻を固定。ファクターごとにRCVを求めたことを思い出しましょう。(8)ですね。平均と標準偏差との比率でしたから、二次元の平面で表現できます。1368のファクターを二次元でプロットしてみましょう。
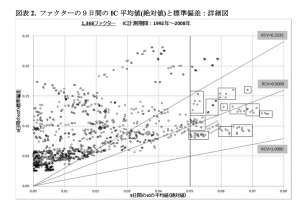
さて、いくつありますか?
プロットは1368あるはずです。容易には数えられませんが。1368のファクターの中で、説明力が高いものを100程度(つまり全体の中の10%程度の選りすぐり)を選びます。説明力とは平均が高く標準偏差が低いもの。それらを平均と標準偏差の近いもの同士でバンドルして14のクラスターに仕分けます。
14のクラスターを選んだら、次に、それらを合成ポジションを作成します。
さらに、その合成ポジションの時系列を20日前、40日前といくつかを遡って計算します。するとRCVの合成ポジションとその変化率が考慮できます。平均/標準偏差の比率が時系列変化であまり変わらないもので、かつ、平均値絶対値が上昇中ならば、それが欲しかったものです。ここで抽出された最終的なRCVはスコア化されます。この最終スコアが銘柄ごとに決定できます。
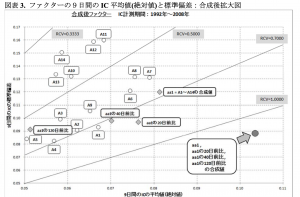
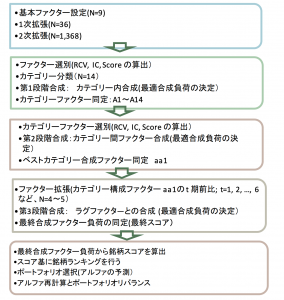
手順は上の通りです。
これまでの説明はたったの一銘柄のある特定の時刻tにおける1368のファクターの働きを説明しました。
これをユニバース銘柄でスコアを序列し、あるファクターがとてもよくリターンが説明できて、そのリターンがリスクなく時間と共に増える傾向があるものをロングし、リスクなくリターンが減少するものをショートする。それが検証の結果、月利で4%、年率なら40%を超えるリターンになるというのです。
FDSのサービスを私なんかは、ETFにしてしまえばよいのにと思いますね。私は、別の観点から、何か起こっているぞ、という初期動作の検出機能として同システムはボトムアップリサーチャーへの信号として活用できると思いました。
行列の世界では対称性と交代性というもので世界を表現します。対称行列は対角化可能でしたね。その意味では、固有値を対角に並べることができて、(8)が意味を持ちます。
ユニークな手法に見えますが、大変そうですが、とても重層的で合理的な手法です。このようなシステムを構築するFDSには敬意を払ってしまいます。ファクター合成の基本を勉強できました。
昨日は、3時間ほどの読み合わせでしたが、とても面白い論文でしたね。まだまだ、一回読んだだけなので、読み落としていることは多数ありますし、細かいところはわからないところだらけです。箱田先生にお会いした時に少し教えてもらいたいと思いました。
少ない要素から次元を増やしていくことは極めて通常のことで、例えば、aという数があれば、これを規定とすれば、a^kを考えてkを無限個用意すれば無限の次元が簡単に作れます。sinもcosもexpもlnもみんな無限次元の関数です。X_jという基底に残差をかけると、見かけ上は、e_i x X_jのように見えるかもしれませんが、e_iの中には全てのX_kたちが入っているので、実際は、すベテ-X_i X_jたちの集まりになり、違う基底となります。平行移動した(X_j + A) という要素を用意して、それとX_jたちとのクロスセクションは、多項式の観点からは単なる共分散の二乗のtermの集まりの単調さから脱してより豊かな表現が可能になると思われます。
お知らせ Encounter with Math 12/6-12/7
中大Endounter with Math #74は12/6 & 12/7 の両日、開催します。K3曲面-その魅力と広がり-について。私は裏方でお手伝い。
京都大学 数理研の向井先生などにご登壇していただきます。お手番の後、億の近道の四季報セミナーへ移動の予定です。
http://www.math.chuo-u.ac.jp/ENCwMATH/ewm74.pdf
筆者について
山本 潤 (やまもと じゅん)
ダイヤモンドフィナンシャルリサーチ投資助言部にて投資判断者を務める。株の学校長期投資ゼミの講師。コロンビア大学大学院修了。哲学・工学・理学の3つの修士号取得。外資系投資顧問のファンドマネジャー歴22年。
日本株の成長株投資を得意としている。外資系投資顧問会社クレイ フィンレイ日本法人共同パートナーで日本株及びアジア株の運用などを経て投資教育の会社を設立。現在も年間400社前後の会社訪問と投資判断を行っている。
1997-2003年年金運用の時代は1,000億円を運用。
その後、2004年から2017年5月までの14年間、日本株ロング・ショート戦略ファンドマネジャー。
過去20年超の機関投資家としての運用戦績は年ベースで18勝4敗の勝率8割超。
現在は、DFR(ダイヤモンド フィナンシャル リサーチ)投資助言部において日本株ポートフォリオ22銘柄で投資判断の助言サービスを行っている。2019年11月29日現在、年初来では29%を上回る成績を提供している。許容ポートフォリオ変動率は20%に設定。売買回転率の実績は年率55%。